Harnessing AI–human synergy for deep learning research analysis in ophthalmology with large language models assisting humans
'%20fill='white'%20fill-opacity='0.01'/%3e%3cmask%20id='mask0_3477_29692'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='0'%20width='16'%20height='16'%3e%3crect%20id='&%23232;&%23146;&%23153;&%23231;&%23137;&%23136;_2'%20x='16'%20width='16'%20height='16'%20transform='rotate(90%2016%200)'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_3477_29692)'%3e%3cpath%20id='&%23232;&%23183;&%23175;&%23229;&%23190;&%23132;'%20d='M14%205L8%2011L2%205'%20stroke='%23333333'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
关键词
摘要
Background: Research innovations in ocular disease screening, diagnosis, and management have been boosted by deep learning (DL) in the last decade. To assess historical research trends and current advances, we conducted an artificial intelligence (AI)–human hybrid analysis of publications on DL in ophthalmology.
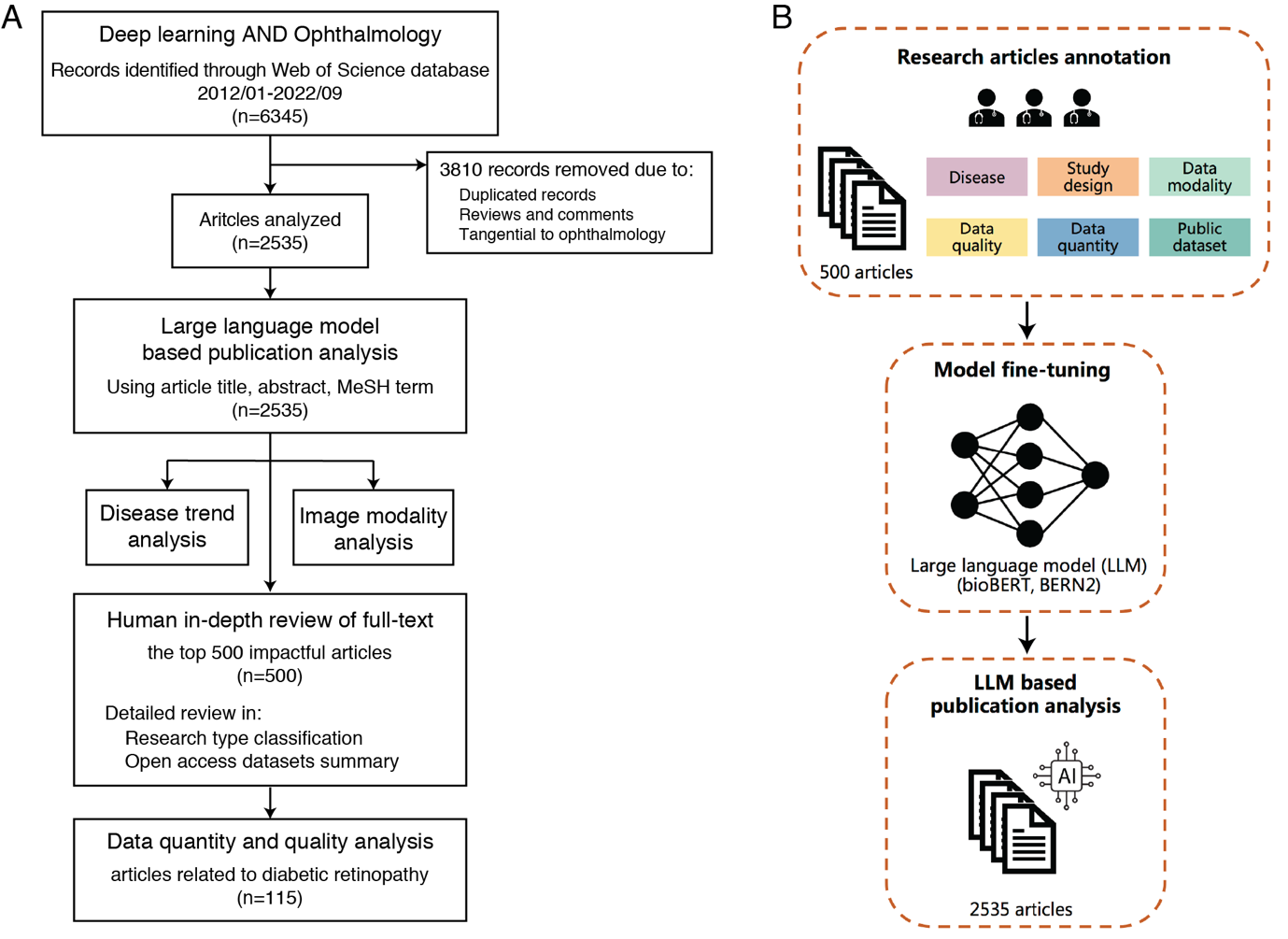
Methods: All DL-related articles in ophthalmology, which were published between 2012 and 2022 from Web of Science, were included. 500 high-impact articles annotated with key research information were used to fine-tune a large language model (LLM) for reviewing medical literature and extracting information. After verifying the LLM's accuracy in extracting diseases and imaging modalities, we analyzed trend of DL in ophthalmology with 2 535 articles.
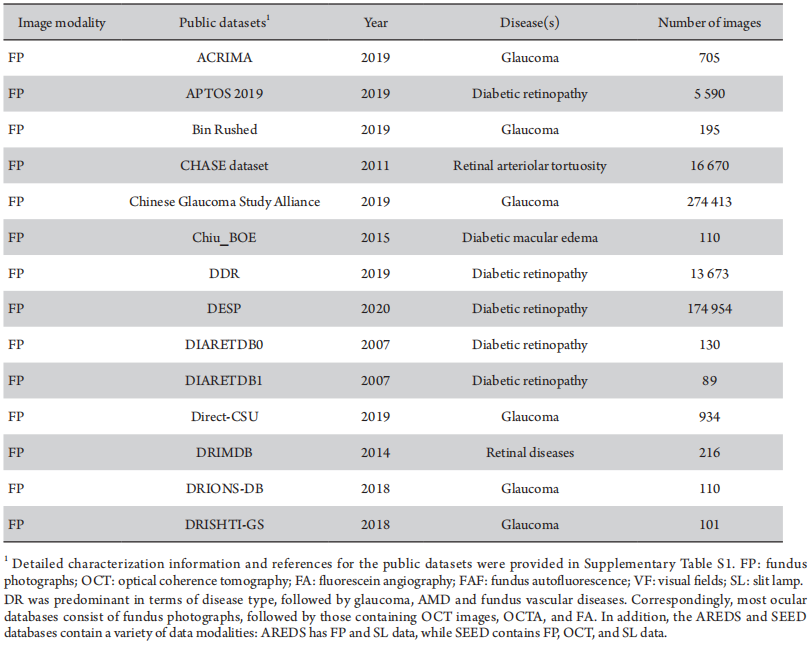
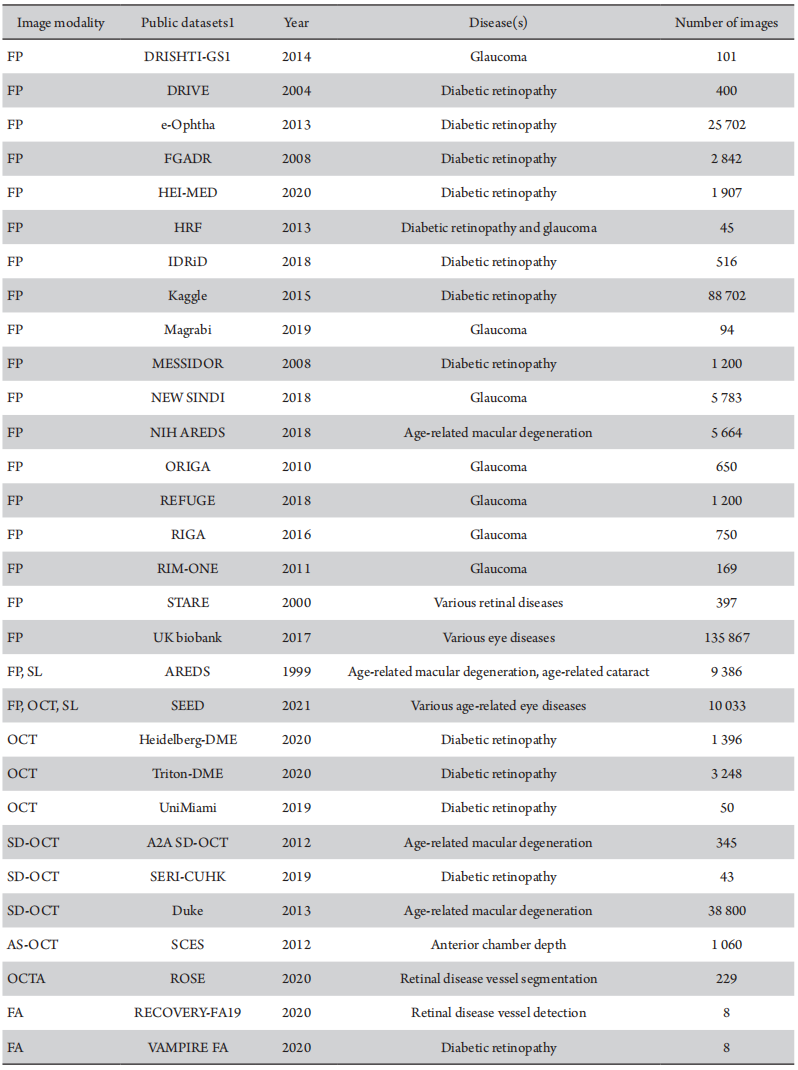
Results: Researchers using LLM for literature analysis were 70% (P= 0.000 1) faster than those who did not, while achieving comparable accuracy (97% versus 98%, P = 0.768 1). The field of DL in ophthalmology has grown 116% annually, paralleling trends of the broader DL domain. The publications focused mainly on diabetic retinopathy (P= 0.000 3), glaucoma (P = 0.001 1), and age-related macular diseases (P = 0.000 1) using retinal fundus photographs (FP, P= 0.001 5) and optical coherence tomography (OCT, P= 0.000 1). DL studies utilizing multimodal images have been growing, with FP and OCT combined being the most frequent. Among the 500 high-impact articles, laboratory studies constituted the majority at 65.3%. Notably, a discernible decline in model accuracy was observed when categorizing by study design, notwithstanding its statistical insignificance. Furthermore, 43 publicly available ocular image datasets were summarized.
Conclusion: This study has characterized the landscape of publications on DL in ophthalmology, by identifying the trends and breakthroughs among research topics and the fast-growing areas. This study provides an efficient framework for combined AI–human analysis to comprehensively assess the current status and future trends in the field.
全文
Recent publications on DL in ophthalmology has shown explosive growth. These publications provide wealth of valuable information about the changing trends in DL-assisted diagnostic systems for ocular diseases, along with a comparative analysis of the development status in different countries worldwide. This field acts as an excellent demonstration of the evolution of medical AI, showcasing changes in various aspects and providing insights into future trends. Nonetheless, published literature reviews or expert consensuses have largely focused on specifc research areas or highly cited articles,[6–9] limiting their scope and providing only a narrow perspective on the overall changes in the field of DL in ophthalmology. Consequently, comprehensive insights into the broader dimensions of ophthalmic AI have been difcult to obtain, such as the trend of research in ocular diseases, changes in data modalities, quantities and quality of research data, along with the factors affecting the DL model performance.[10] Additionally, manually reading and analyzing through such a large volume of literature is a time-consuming and challenging task, and might lead to a biased representation of the overall perspective.[11] It is urgently needed to conduct a comprehensive and practical overview of this fast-evolving feld.
Recently, large language models (LLM) have shown significant success in following instructions and producing human-like responses.[12-13] Using LLM for natural language processing and applying the state-of-the-art bibliometric analysis in joint with human experts, this study presented a comprehensive overview of the evolution in this rapid changing research feld. Base on this, we have identified trends and challenges among common ophthalmic DL research and further provided prospects for future applications. Additionally, this study offers a practical approach to comprehensively investigate current status and future trends in the field, making it a valuable reference for other researchers.
Diseases and Data Modalities in Ophthalmic DL Research
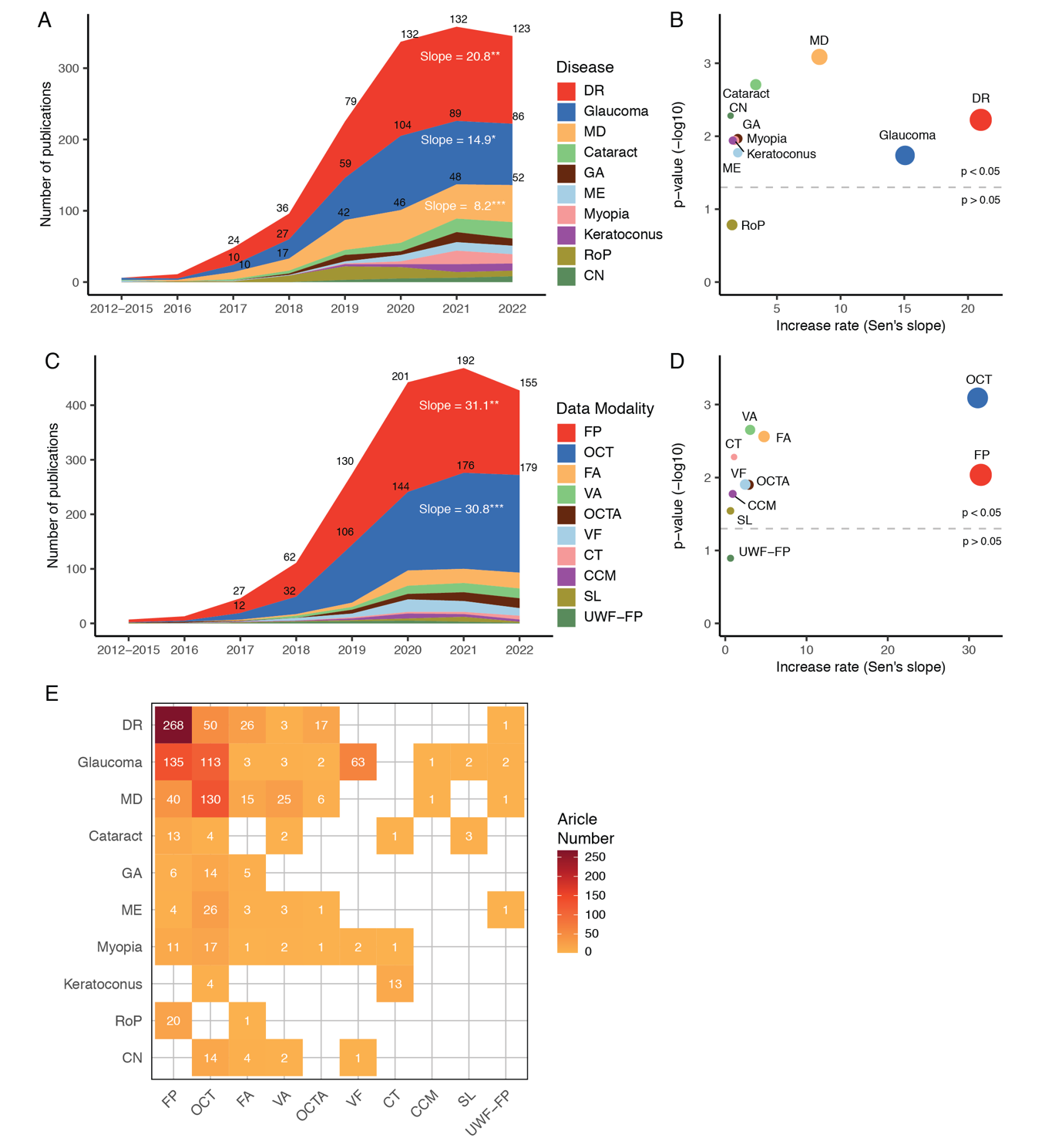
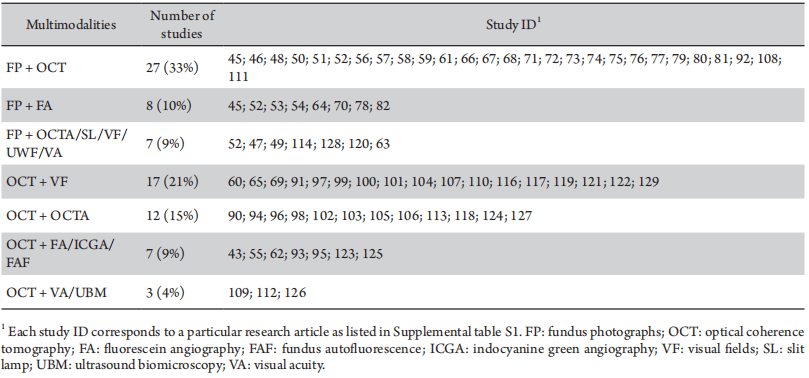
The 10 most commonly studied diseases were shown in Figure 3A, including DR, glaucoma, macular degeneration, cataract and fundus diseases. As stated here, researchers related to various ocular diseases began to gradually increase in 2016 and showed a significant increase between 2017 and 2020. The most studied on ocular diseases are DR, glaucoma and macular degeneration, which have also shown an increasing trend in the last 10 years, with Sen’s slopes of 20.8 (p = 0.000 3), 14.9 (p = 0.001 1) and 8.2 (p = 0.000 1), respectively (Figure 3B).With similar methods, the data modalities used were extracted and summarized. The top 10 data modalities in terms of growth rate were ranked on Sen’s slope (Figure 3C). As stated, DL studies using fundus photographs (FP) and OCT began to rapidly increase in number and gain prominence in 2018, with Sen’s slopes of 31.1 (p = 0.001 5) and 30.8 (p = 0.000 1), respectively (Figure 3D). Many other data modalities including fluorescein angiography (FA), optical coherence tomography angiography (OCTA), visual acuity (VA), visual fields (VF) and corneal topography (CT), have been increasing applied since 2020. The data modalities used in studies of different ocular diseases varied considerably (Figure 3E). Specifically, studies on DR mainly used OCT and FP; studies on glaucoma relied mainly on OCT, FP, and VF; and macular degeneration studies relied on OCT and FP. Additionally, several DL studies used multimodal ophthalmic data (Table 1). 27 (33%) multimodality studies involved both FP and OCT images, 17 (21%) used OCT and VF, and 7(9%) studies utilized FPand one of the modalities such as OCTA, slit lamp (SL), and VA.
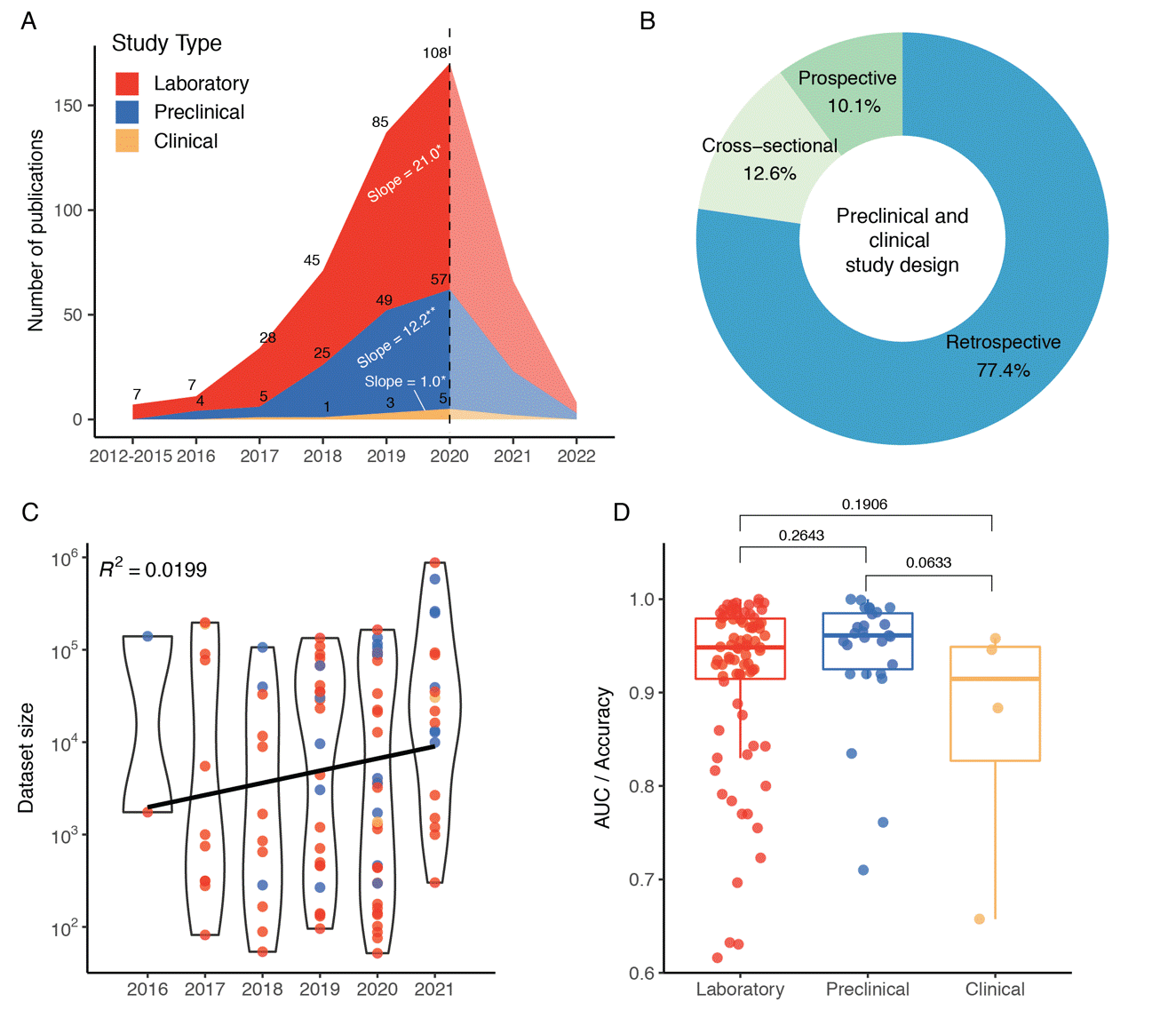
The dataset size and fnal model performance used in the 115 DR studies were compiled. This is to determine whether a large data size is necessary to train a model with adequate performance (Figure 4C). The interquartile range (IQR) of the data size for DR classifcation models is 462–74,198 images, and the average data size has grown from 70,817 images in 2016 to 122,810 in 2021, with an average annual increase of 10,398 (14.7%) images. By dividing the presented performances in these studies according to the study design, it was revealed that the average accuracy of the models declined consistently (Figure 4D).
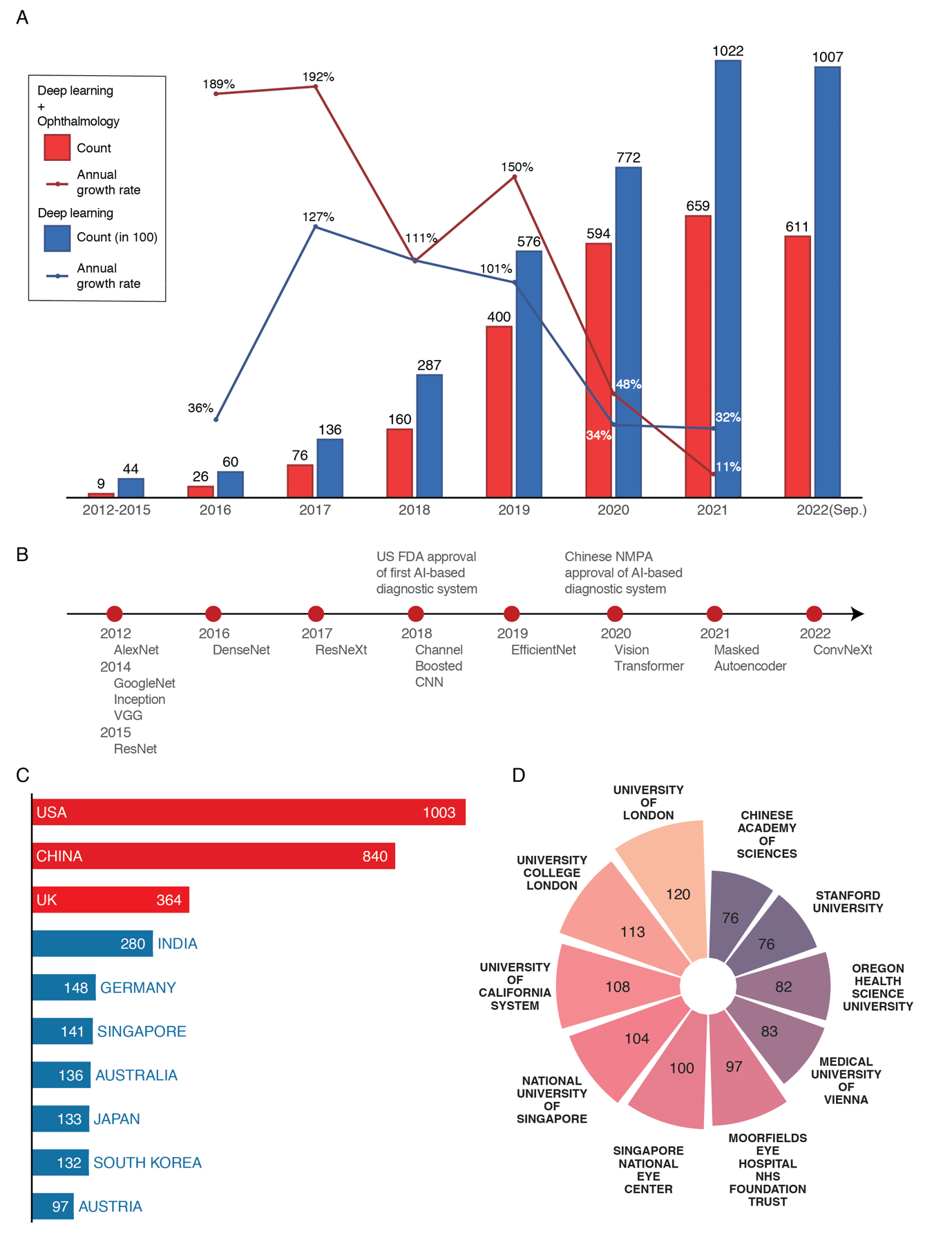
Advances in the DL field have accelerated DL research in ophthalmology. From 2012 to 2015, there were revolutionary developments in the DL field, including the construction of benchmark image datasets ImageNet,[16] COCO[17] and development of convolutional neural network architectures such as AlexNet[18] and ResNet.[19] The subsequent rapid growth of DL research in ophthalmology occurred as a result of these breakthroughs in DL advancing the state-of-the-art and laying the foundation for further research and development of DL in ophthalmology. Many of the leading ophthalmic deep learning studies have come from technologically advanced countries including the United States, China, the United Kingdom, and India. With major research contributions from these countries, deep learning-based diagnostic systems for ocular diseases have gained approval from global regulatory bodies. In 2018, the first U.S.license for such a system was issued,[20] followed by the Chinese license in 2020.[21] This widespread regulatory approval refects the progress in deep learning research and validation of its ability to accurately detect and diagnose eye diseases, signaling a shift from laboratory studies to clinical applications.
Ophthalmic DL research has gradually transitioned from initial feasibility studies to real-world clinical applications. Early feasibility DL studies focused on DR based on FP, as the large patient population and extensive labeled image datasets enabled algorithm development and validation with minimal technical complexity.[22] By establishing capabilities and clinical value on a common ocular disease (e.g. DR) with abundant training data, researchers laid the groundwork to then investigate expanding DL to other ocular diseases.[1] The initial successes have led to further research broadening real-world deployment of DL models across diverse clinical applications, such as telemedicine screening and smartphone-based diagnostic tools at point-of-care.[23-24]
Moving beyond reliance on single data modalities like FP and OCT, there is instead increasing utilization of multimodal approaches that integrate information from diverse clinical exams and tests to enable more comprehensive and accurate diagnosis. This transformation is driven by complex ocular conditions like glaucoma that require assimilating data from basic ophthalmic exams, visual feld testing, cup-to-disc ratios from fundus imaging, and optic nerve layer thickness from OCT to facilitate robust clinical judgments.[25]Moreover, combining other data sources like genomic tests with imaging data has been proven efficacy for predictive modeling in diseases like age-related macular degeneration.[26] As algorithms become more sophisticated, they can synergistically combine disparate inputs from various ophthalmic subspecialties, testing modalities, and data types. By amalgamating these diverse datasets, DL models can mimic multifaceted clinical decision making and enable more precise disease diagnosis and prognosis across ophthalmology.
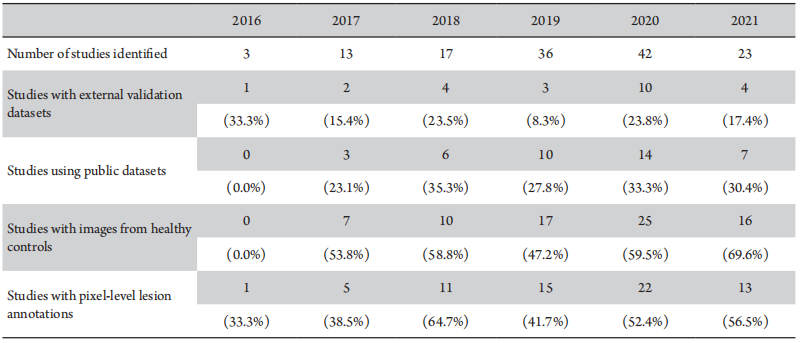
Data quantity and quality are crucial in DL applications in ophthalmology. However, the necessary sample size is contingent upon the complexity of the disease and detection task, as well as the intricacy of the model. In an early experiment, the impact of dataset size on DL algorithm performance in detecting DR was analyzed.[3] The results revealed that peak performance was reached at approximately 60,000 images, suggesting that increasing the dataset size beyond this point did not improve algorithm performance. However, with advancements in DL algorithms, it is now unclear what amount of data is required for optimal performance. By investigating high-impact DL articles on DR detection, our findings indicate that the DL model’s performance decreased markedly from laboratory to clinical studies. This observation implies that the self-reported AUC and other evaluation criteria employed in these studies may not adequately represent the real-world performance of the DL models due to the reproducibility issues.[27]Alternatively, it could be that the data analyzed, extracted from previously published DR-related studies, lack broad applicability to other ocular diseases, which necessitates more rigorous experimental investigations in future studies. Additionally, we found that the proportion of studies using externally validated datasets and public datasets was not high (20–35%) which might be due to the difculty in obtaining resources for external validation datasets and public datasets. The question about the sample size required for deep learning is the one without a standard answer. Determining the optimal sample size for DL studies is challenging due to the disease complexity, specific medical tasks, and the complexity of DL models.[28-29] Given that the results derived from different deep learning algorithms on various datasets cannot be directly compared, it is imperative to establish a unifed and objective standard evaluation method. This will ensure a greater consistency in the assessment of model performance, thereby enhancing the reliability of the outcomes.
This study has several limitations. This study is based on previously published articles, and therefore may not capture emerging trends in research that has not yet been published. Additionally, the citation time-frame used in this study is restricted to high-impact articles published mainly before 2021, resulting in fewer articles from 2022 onward that were included in the refined analysis. To obtain more concrete conclusions, a more robust study with a larger sample size is warranted. Although we analyzed ophthalmology research trends, data modality, volume, and types of studies, some other aspects of deep learning in ophthalmology research were not addressed in this paper. These aspects include data privacy and security, interpretability and transparency of AI models, and regulation and standardization of AI in practical applications. There are some articles that are not indexed in PubMed and do not have MeSH words, which is mitigated by our thorough analysis of titles and abstracts, ensuring a comprehensive review that minimizes the impact of this limitation on our study's fndings.
In conclusion, we showed that an LLM combined with in-depth manual analysis were capable of reviewing medical literature and extracting information. Using the LLM–assisted approach, we have identified trends and challenges among common ophthalmic DL research and further provided prospects for future applications. This includes the necessity of validating AI models via real world clinical setting, and creating standardized, public accessible datasets to enhance collaboration, benchmarking for DL applications. Additionally, this study offers a practical approach to comprehensively investigate current status and future trends in the field, making it a valuable reference for other researchers.
Correction notice
NoneAcknowledgement
NoneAuthor Contributions
(I) Conception and design: HTL,DRL,MJL,ZZL(II)Administrative support: HTL, DRL
(III) Provision of study materials or patients: HTL, DRL
(IV) Collection and assembly of data: MJL, WXZ, ZMZ, JYP
(V) Data analysis and interpretation: MJL, JYP, ZZL, LQZ
(VI) Manuscript writing: MJL, WXZ
(VII) Final approval of manuscript:All authors
Funding
This study was supported by the National Natural Science Foundation of China (82000946), Guangdong Natural Science Funds for Distinguished Young Scholar (2023B1515020100), the Natural Science Foundation of Guangdong Province (2021A1515012238), and the Science and Technology Program of Guangzhou (202201020522 and 202201020337).The funding organizations had no role in the following aspects: design and conduct of the study; the collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and the decision to submit the manuscript for publication.
Confict of Interests
None of the authors has any conflicts of interest to disclose. All authors have declared in the completed the ICMJE uniform disclosure form.Patient consent for publication
NoneEthical Statement
This study does not contain any studies with human or animal subjects performed by any of the authors.Provenance and Peer Review
This article was a standard submission to our journal. The article has undergone peer review with ouranonymous review system.Data Sharing Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.OpenAccess Statement
This is an Open Access article distributed in accordance with the Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International License (CC BY-NC-ND 4.0), which permits the non-commercial replication and distribution of the article with the strict proviso that no changes or edits are made and the original work is properly cited (including links to both the formal publication through the relevant DOI and the license). See: https://creativecommons.org/licenses/by-nc-nd/4.0/.基金
参考文献
27. Chen B, Wen M, Shi Y, et al. Towards training reproducible deep learning models. In: Proceedings of the 44th International Conference on Software Engineering.; 2022:2202–2214.
28. Rajput D, Wang W-J, Chen C-C. Evaluation of a decided sample size in machine learning applications. BMC Bioinformatics. 2023;24:48.
29. Figueroa RL, Zeng-Treitler Q, Kandula S, Ngo LH. Predicting sample size required for classification performance. BMC Medical Informatics and Decision Making. 2012;12:8.